
Framework Desktop Hands-on: First Impressions
So it’s time to talk about the Framework Desktop! We mentioned it back in March 20025 ahead of its release. It’s a significant machine for Framework for several reasons:
- it’s their first foray in the Desktop (or mini-desktop) category
- it’s also their first machine that is not entirely upgradeable
Framework has built its brand on delivering devices to end users that can be easily opened, upgraded, and repaired. Moving to a desktop where the RAM is now soldered (LPDDR5x RAM) on the mainboard is a kind of step back.
I believe they saw it as a great opportunity to market something different even if it strayed from their current line-up and ethical considerations. The core of this machine is the STRIX Halo APU from AMD, a true beast that’s not just about great compute power, but also a powerful integrated graphics chip. And in my case, what makes it even more interesting is the fact that it has a large amount of integrated RAM/VRAM that can be leveraged to run AI models (more specifically LLMs).

Framework has been kind enough to provide us a sample of the machine ahead of the release. Since I have only had the machine for a couple of days at the time of writing, this is NOT going to be an extensive review right now, but my first impressions so far with the machine. I wanted to get this out fairly quickly so that anyone interested can consider if it’s fit for specific purposes.
As usual I’ll cover the positives and where there is also room for improvement.
Hardware
Specs
The hardware comes in a few different versions, centered around the Ryzen AI Max 385 or 395 chips.
| Feature | AMD Ryzen AI Max 385 | AMD Ryzen AI Max+ 395 |
|---|---|---|
| CPU Cores | 8 | 16 |
| Threads | 16 | 32 |
| L3 Cache | 32 MB | 64 MB |
| Base Clock | 3.6 GHz | 3.0 GHz |
| Max Boost Clock | Up to 5.0 GHz | Up to 5.1 GHz |
| Integrated GPU | 32-core AMD Radeon 8050S, 2800 MHz | 40-core AMD Radeon 8050S, 2900 MHz |
| NPU | 32 Tiles, up to 50 TOPS | 32 Tiles, up to 50 TOPS |
| Soldered Memory | 32 GB LPDDR5x-8000 | 64 GB or 128 GB LPDDR5x-8000 |
In my case I got the configuration with the largest amount of RAM available (128 GB), and 16 cores / 32 threads. Once you start having such a number of cores the htop / btop view becomes fairly cluttered by the CPU metrics:
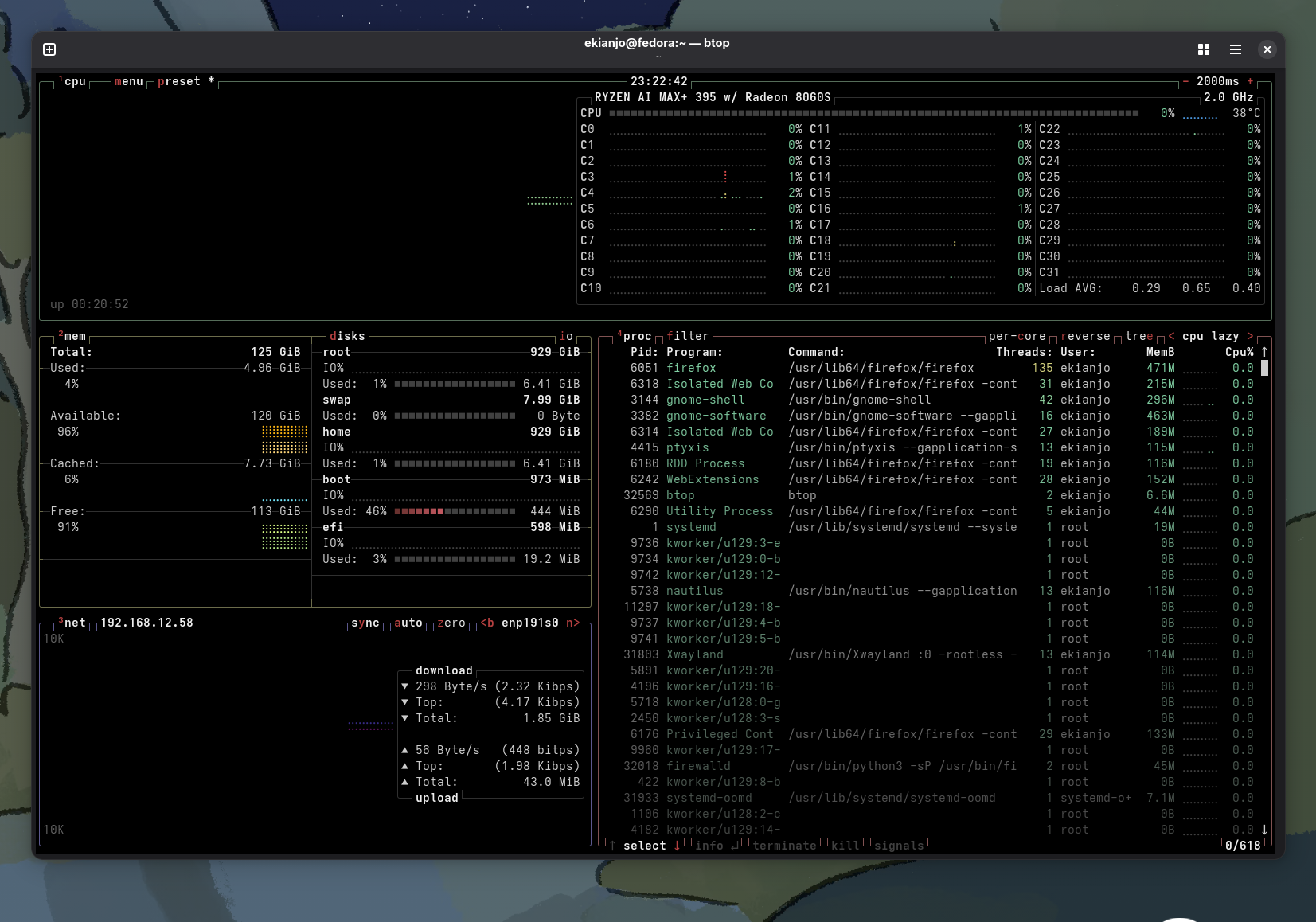
The AMD Radeon 8060S is a powerful integrated GPU found in the APU. It’s built on the RDNA 3.5 architecture and is designed to deliver performance that rivals many mid-range discrete graphics cards. Its key feature is its large number of compute units and its access to a significant amount of shared system memory (not all, unfortunately).
You can find the specs below.
| Feature | Specification | Details |
|---|---|---|
| GPU Architecture | RDNA 3.5 | An iteration of AMD’s RDNA 3 architecture, optimized for APUs. |
| Compute Units (CUs) | 40 | A high CU count for an integrated graphics solution. Each CU contains 64 stream processors. |
| Stream Processors | 2,560 | Total number of shading units available for parallel processing. |
| Ray Tracing Cores | 40 | One ray-tracing core per compute unit, supporting hardware-accelerated ray tracing. |
| TMUs (Texture Mapping Units) | 160 | Used for applying textures to 3D models. |
| ROPs (Render Output Units) | 64 | Responsible for the final pixel output. |
| Boost Clock Speed | Up to 2,900 MHz (2.9 GHz) | The maximum clock speed the GPU can reach under favorable conditions. |
| Memory | Shared System Memory | The GPU uses the system’s LPDDR5x RAM for its video memory (VRAM). |
| Memory Bandwidth | Up to 256 GB/s | This is achieved by utilizing the high-speed LPDDR5x-8000 system memory. |
| VRAM Allocation | Up to 96 GB | AMD’s “Variable Graphics Memory” allows the system to allocate a large portion of its unified RAM to the GPU. |
| Process Node | TSMC 4 nm | A modern, efficient manufacturing process that allows for high performance in a compact form factor. |
| API Support | DirectX 12 Ultimate | Supports modern graphical features, including hardware-accelerated ray tracing and variable rate shading. |
| Display Support | Up to 4 monitors | Supports resolutions up to 8K at 60Hz and high refresh rates at 4K and 1440p. |
| Theoretical Performance | Up to 11.96 TFLOPS (FP32) | A high number that indicates the GPU’s raw processing power. |
What you get in the box
As expected from Framework, you get some fairly nicely packaged parts that are reminiscent of what Apple does. The kind of package where throwing them away would make you feel bad.

My shipment was for the mainboard only, so I used a different mini-ITX case to fit the hardware inside. First warning here, the way things are arranged in the Framework Desktop’s own case may different from what you expect from a regular PC. For example, the Framework Desktop case expects the PSU to be very close to the top of the mainboard, while my Mini-ITX case expects it below. So… the PSU did not fit where it should. I have fixed this with extension cables, but this may be one of the few surprises you run into if you are not careful with the case you choose.
Why would you want to order the Desktop without its own case, by the way? There are several reasons actually. My Mini-ITX case has extra space for a GPU to be attached through a PCI Express extended port. Not a huge GPU, but one that can fit in about 20 centimeters or so at least.
Other reasons are… looks. I have to say, as much as I usually like the clean design of the Framework brand, I was not thrilled by the outside of the case and its removable blocks. I understand they wanted to look different from a regular one piece of metal casing, but this is something else. The case itself is however very well designed and everything fits very neatly together in it, in a very compact format.

The mainboard has a HUGE heatsink. I knew what to expect from the pictures, but seeing it in real is still impressive. And it does not stop there, as they bring a big ass 20 cm diameter fan to go on top of it. The advantage of a very large fan is that it can remove a lot of heat at lower RPMs, making the Desktop very, very quiet. I have pushed the machine to fairly high workloads and most of the time the heatsink will deal with it and the fan will not rotate at all.

Once you reach around 70C you will see the fan kicking off, and very quietly shaving heat from the board. It’s a wonderful design, really. True, the heat sink and the fan end up taking a large amount of space, but since it’s so quiet, you can definitely considering putting this machine on your desk.
OS: This time we go with Fedora
Framework recommends to use Fedora 42 with this machine as everything is well supported out of the box - no need to install any additional patches or drivers. This was also my first time using Fedora (!) as I’ve tried almost everything under the sun until now expect that branch of the large Linux distribution tree. And I was very pleasantly surprised. The install process is super smooth, the desktop (GNOME based) is clean, and everything works out of the box indeed with this machine,including the graphics drivers.
Benchmarks
I’m sure you want to see some benchmarks. This machine has a fairly powerful CPU and a very capable integrated GPU. As a package, it’s very solid, and as you can see below it will do well in a number of applications.
Blender
Before moving to benchmarks I tested a rendering of the classroom scene that you can find on Blender examples. It was pretty fast, with about 5 minutes more or less to produce this full render.
The Blender benchmark tool is mostly driven by the GPU performance - when used as a compute unit. There is also a different mode that focuses on CPU only. Let’s start with that one - we get the following results:
And you can see some other processors who are roughly in the same ballpark in terms of total score:
Now if we let blender use the integrated GPU, the rendering speed becomes much, much faster, and the score jumps above 1000.
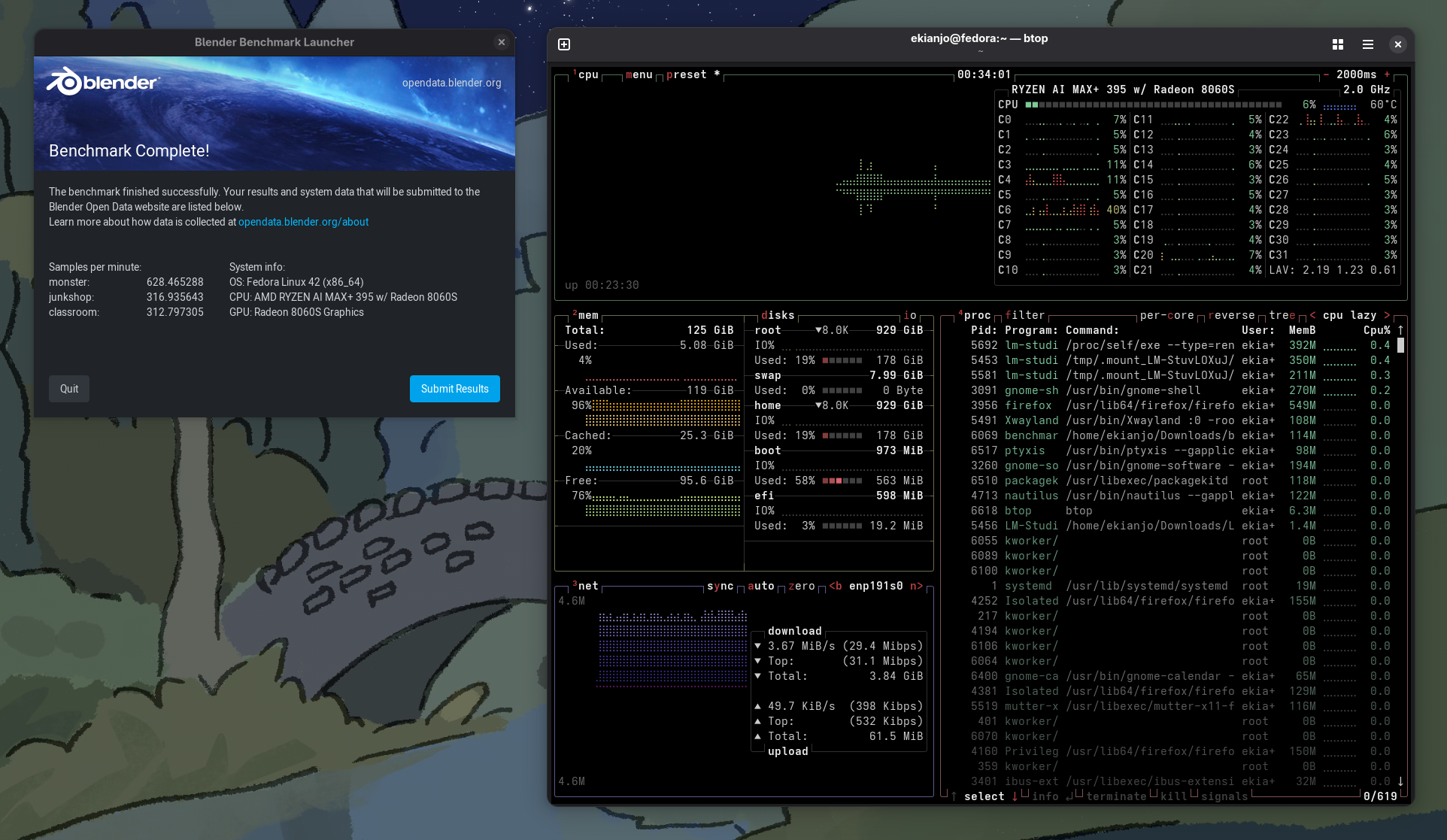
In the same range you get the following results from other configurations:
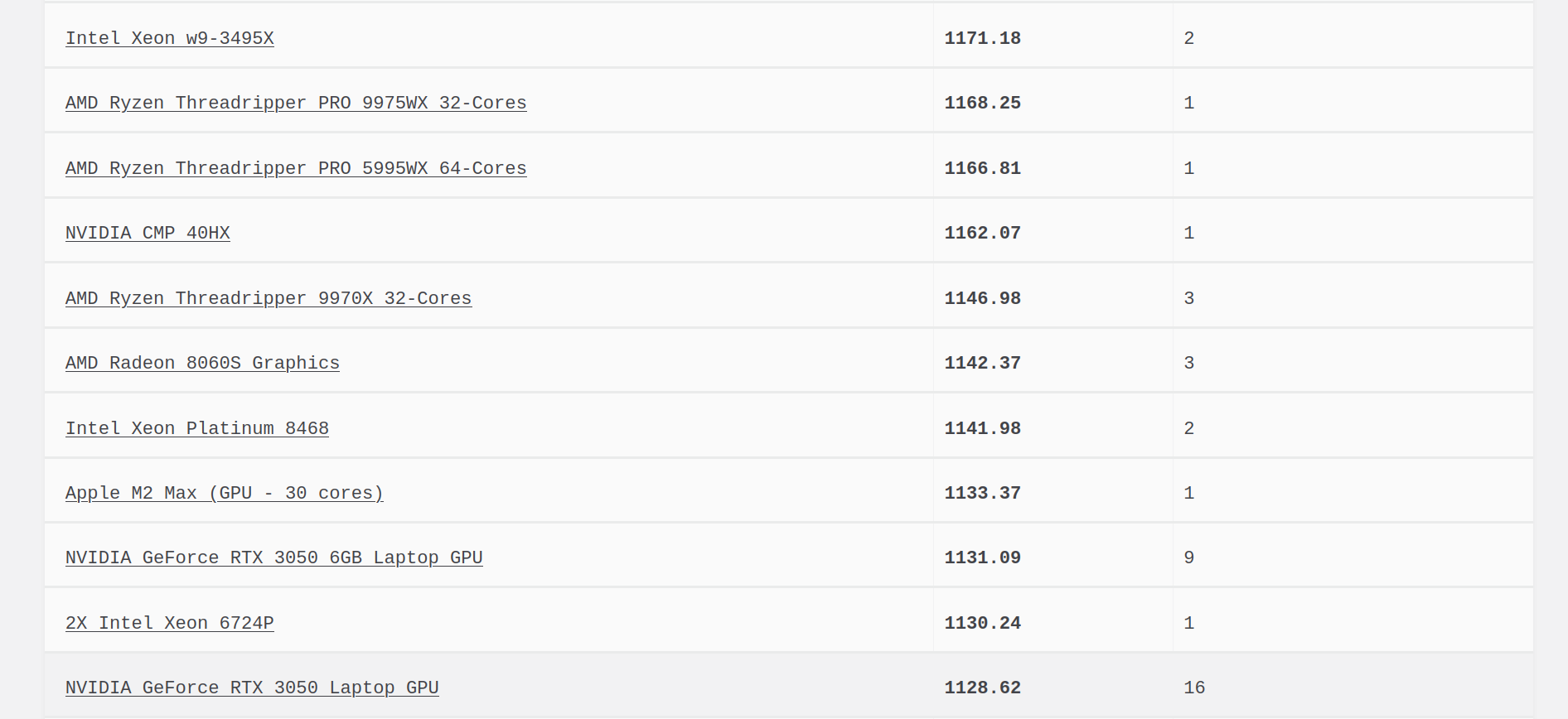
What is pretty cool is that you get a performance for rendering close to an AMD threadripper (CPU only, of course), or close to a M2 Max from Apple. Very decent results.
Unigine Superposition
This benchmark is also heavily influenced by the GPU performance - and it used OpenGL (not Vulkan). If I have to compare with my other machine sporting a RTX3090, of course the Strix Halo loses, but its performance is far from ridiculous for an APU.

It gets a score slightly about 6000, which is equivalent to a mid-range CPU running with a GTX1080 Ti or a RTX2070. Not bad for an APU!
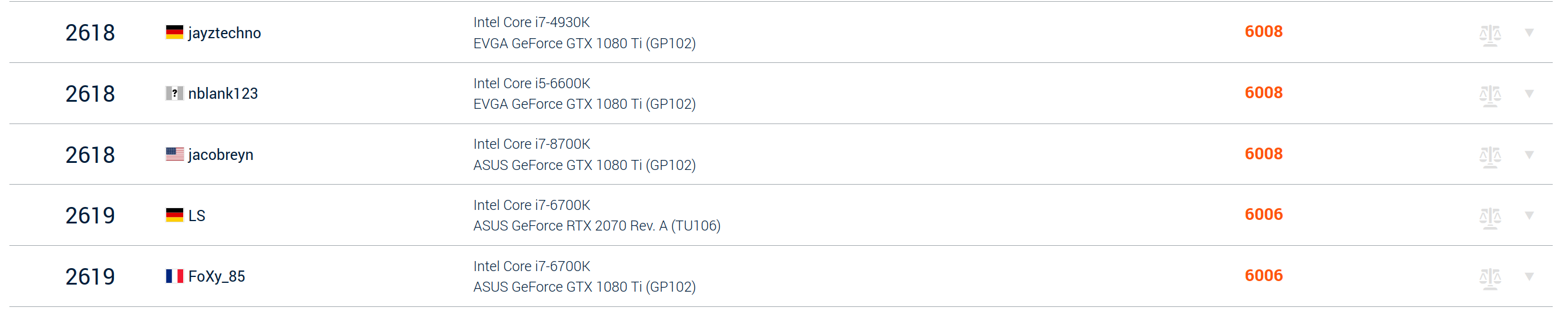
The claims that the APU is roughly equivalent to a RTX 4060 does not seem too far off.
Gaming
I did not have much time to play a lot of games, but hey, Clair Obscur: Expedition 33 is a very recent title, running on Unreal Engine 5 and kind of demanding, so why not try it out? And I did. And it runs well!

It would definitely run at 60 fps if you tweak the settings a little bit, even at high resolutions (I play on an Ultra-wide monitor, so 3440 x 1440 pixels).
I will have to try out a lot more games, and that will be for a separate article.
Because of the small form factor, it looks like you could easily turn this machine into a powerful home console, running SteamOS (or Playtron). It’s a little bit on the expensive side if you use it only for that, but it would crush a PS5’s performance easily without a sweat. The chip itself is too big for a handheld usage, so it would probably not be a good fit for a future Steam Deck 2.
Running LLMs with the Framework Desktop
One of the most interesting aspects beyong gaming for this hardware is to turn it into an LLM server. Its memory bandwidth is a little weak (256 Gb/s) compared to the recent Mac Studios, but the large pool of memory makes it possible to load very large models directly on the shared GPU memory for full GPU offloading. This means you can things like the latest Qwen3 models on GPU memory! A very exciting prospect.
You could also sun the GPT-ass (sorry, oss) models (at least the 20b) from OpenAI, if they were not terrible (they are, don’t waste time). Funny that in mid 2025, we are in a situation where the best open models come from China and not the US anymore. The Llama models used to be a reference and have completely dissappeared from the radar after a very lame 4.0 release a few months back. And Meta seems to be focused on closed models now, instead.
So, Qwen, Deepseek, Kimi, all the way, I guess.
LM Studio and Shared Memory
LMStudio is the recommended way to use the Framework for its LLM capabilities. Since I typically go for FOSS, I had never tried LMStudio belore, which is a proprietary freeware solution. My go to LLM server setup would usually be either Ollama or llama.cpp directly.
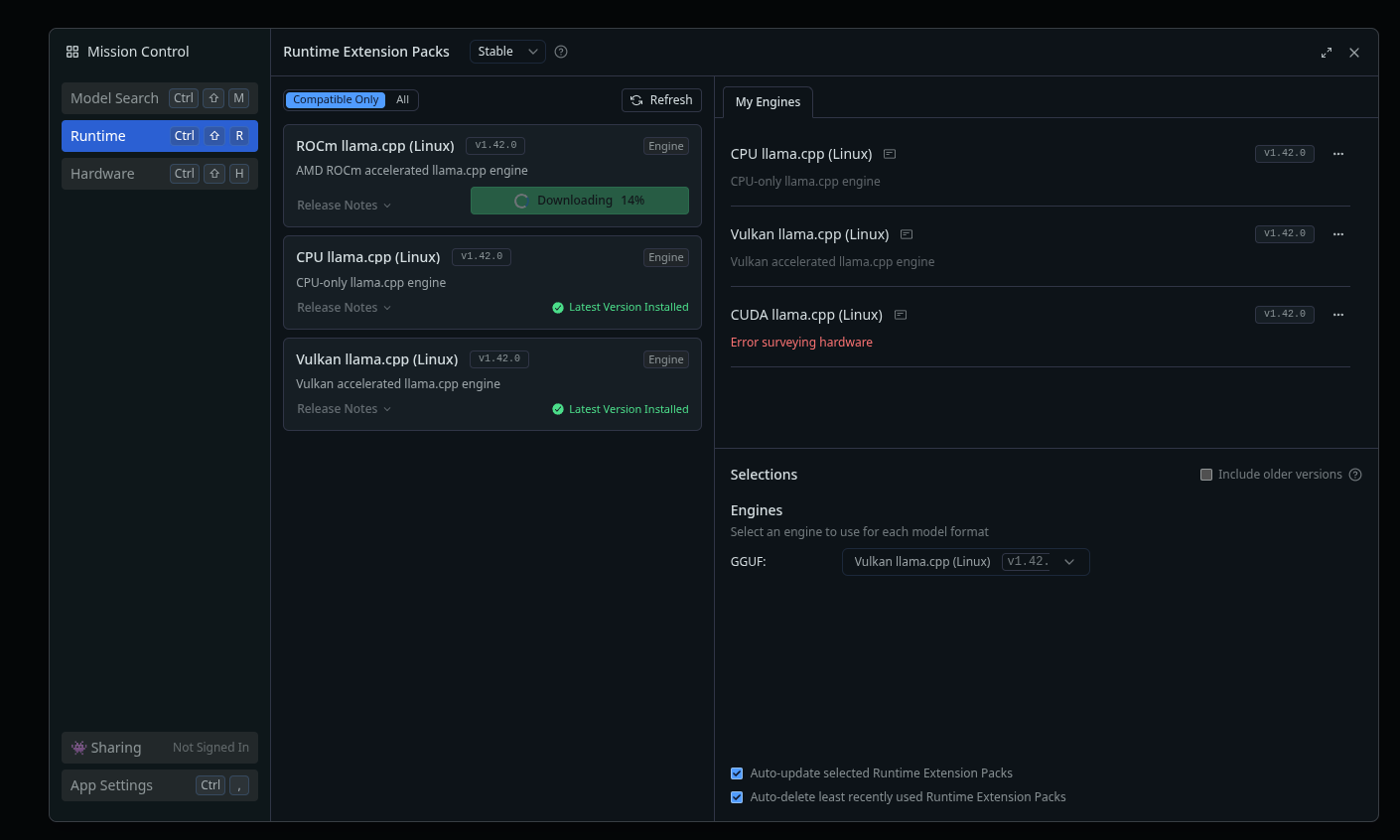
There are three different modes you can use with LMStudio to run the models:
- Raw CPU power.
- Vulkan backend, with about 40 GB of VRAM available.
- ROCm backend, with about 60 GB of VRAM available.
You can see the Vulkan runtime with its memory footprint here:
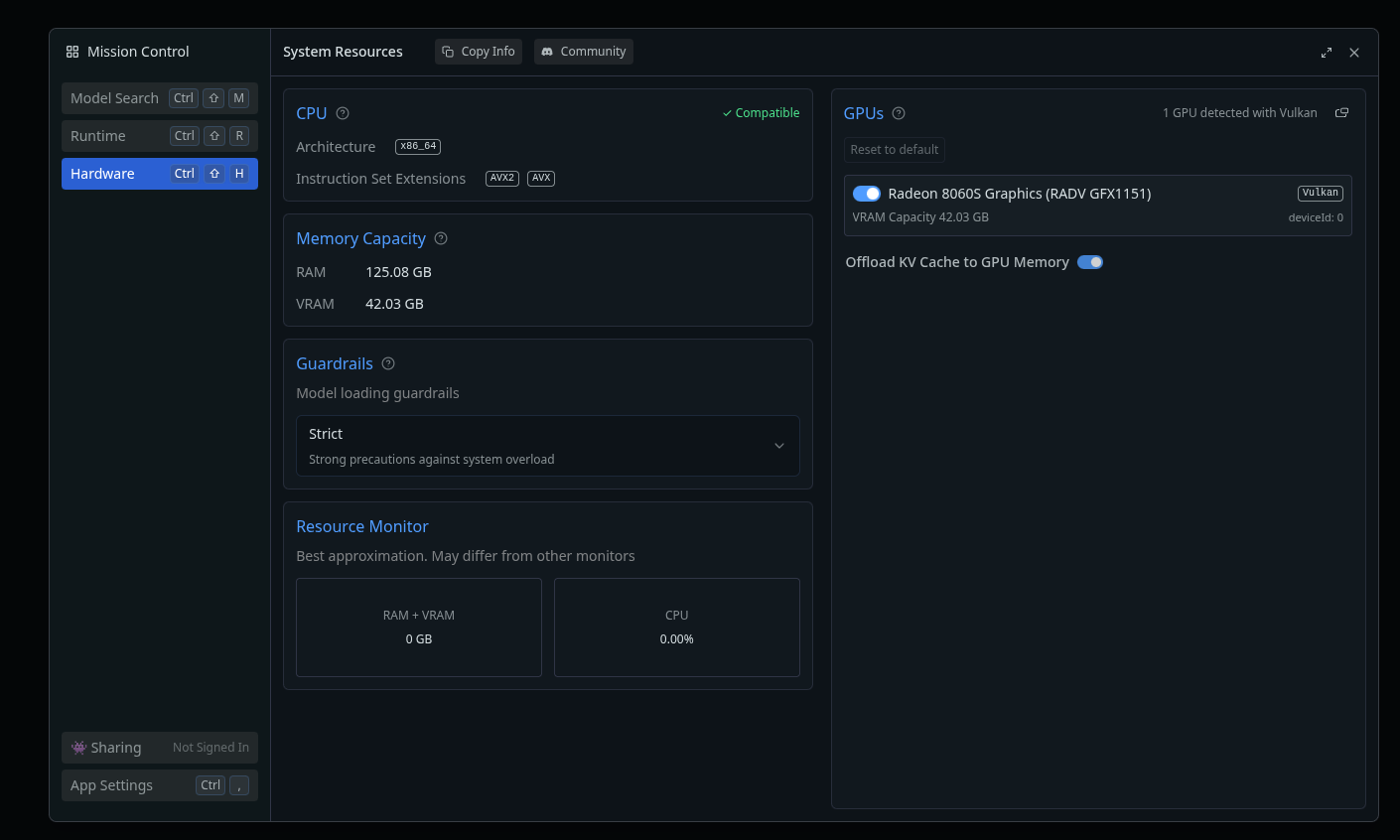
One warning though, I could not make the ROCm backend work at all. Loading models with it led to crashes and no inference results. I guess this is some kind of drivers issue with the ROCm stack, I will have to investigate that. Framework seems to recommend using the Vulkan backend anyway, so you end up with 40GB of usable VRAM, which is still great.
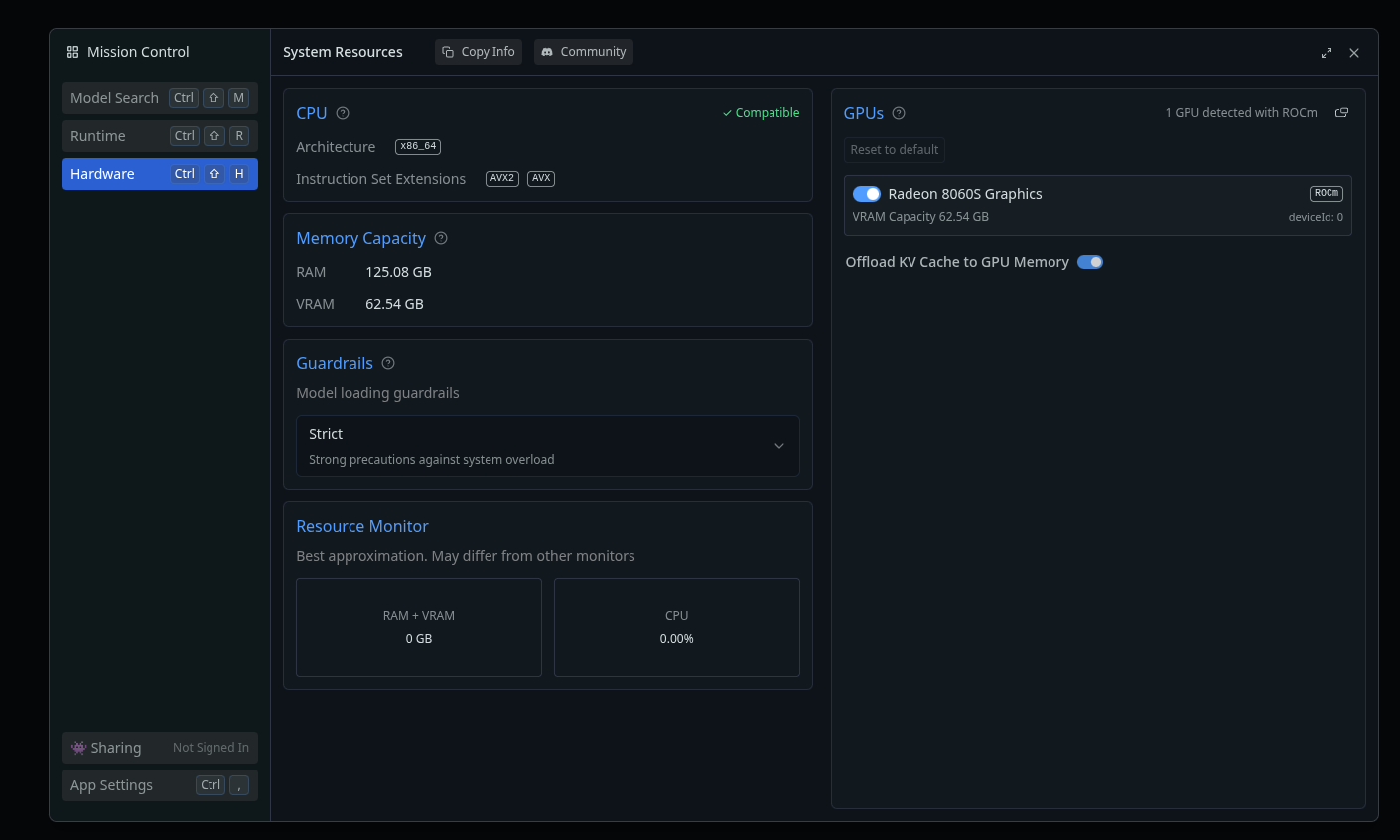
Don’t forget that on the GPU side of things, you are mostly limited, in the consumer offering, to 24GB (RTX3090 and 4090) or 32GB maximum (RTX5090, once you sell a kidney). So you can go beyond that, and while the GPU cores will be weaker than the CUDA cores on Nvidia cards, the fact that you can offload everything on the GPU will give it an edge for models that are bigger than what a Nvidia GPU can load.
The other advantage is that you could load several models at the same time on the Framework Desktop, and switch between them without drop in performance, while a Nvidia setup with less VRAM would suffer from unloading/loading delays between models. A few seconds here and there end up making a difference.
I tried very quickly Qwen Coder30B with something that’s typically expected from benchmarks these days: to generate an HTML page with javascript to simulate the movement of planets in the solar system. It worked very well (with a few minor problems to fix) as you can see below:
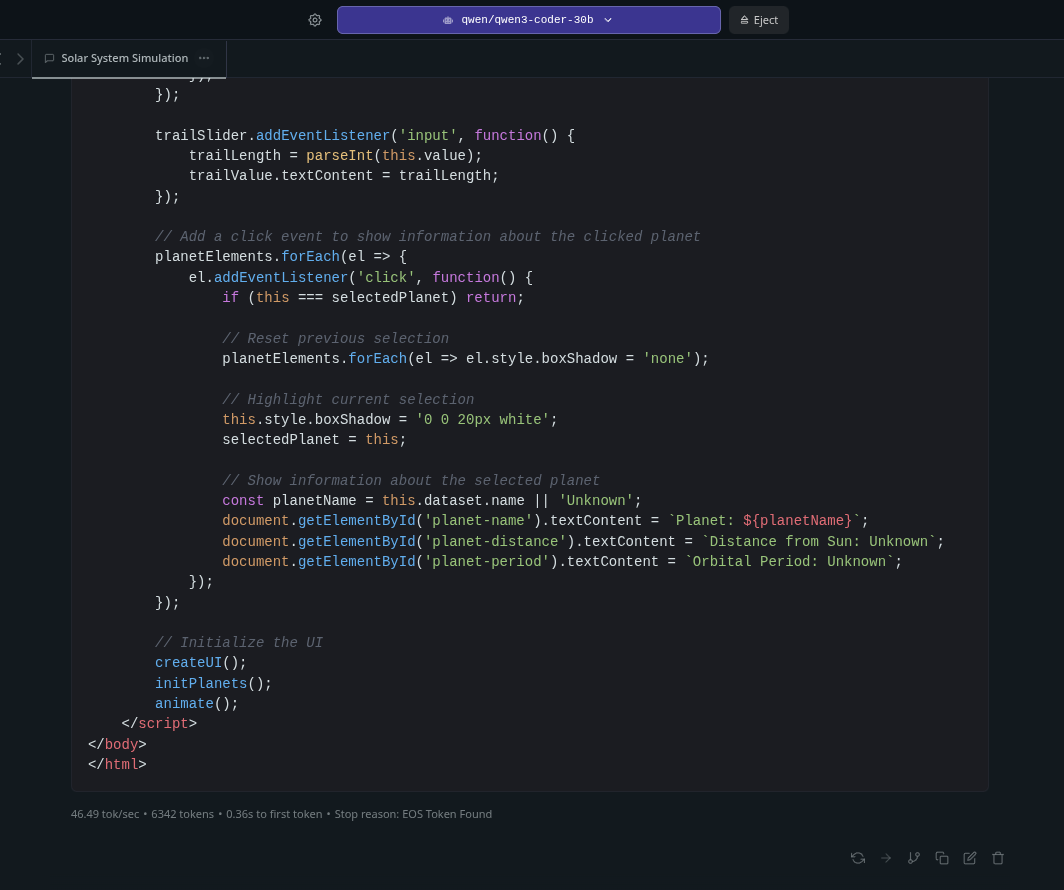
The generation was pretty fast, with about 46 tokens per second! For a 30b model, this is very decent speed.
Of course, this is with a very empty context. Once you start adding a larger context, the pre-processing time becomes longer. I tried giving to Gemma3-27b the whole book of Alice in Wonderland, and as expected, the context length of more than 40k tokens becomes a huge burden for this kind of machine (at least 5 minutes wait). A Nvidia GPU (with enough VRAM) will pre-process such a context in no time, but the Framework Desktop and the Mac Studio will face the same issue: very long contexts will make them slow.
I tried again with a model where the context would fit in the GPU memory (Qwen3-30B-A3B), and the context was absorbed faster (in 320 seconds), and the subsequent summary was provided at 12 tokens/s.
Summarizing a book is difficult task, but you can now have models that can take a huge chunk of context and deal with it. Whether the summary is of a good quality is a different metric to look at, but this kind of things is becoming increasingly possible.
Of course, if the time to first token is what matters to you, you will need to be patient with this kind of hardware. So if you use case is to vibe-code on a a large codebase using Aider or Cline with the Framework Desktop, you will need to be take your time.
If your use cases are mostly around smaller contexts, around a pure replacement for a typical ChatGPT session with local models, where you simply ask a few questions on a single topic at a time, it will be just fine, and quite fast.
Overall
First impressions are very positive so far.
This is a very powerful machine that fits nicely in a small case, and remains extremely quiet in most situations, thanks to the heatsink and the huge fan design. Gaming capabilities seem to be solid, while I will have to revisit this in more details.
As for the promise of a LLM powerhouse, it’s more or less what I expected: something similar to what you see on Mac Studio: able to fit large models into VRAM, capable of fairly fast inference (it gets slower as you work with denser, larger models, so anything beyond dense 30b is going to be borderline usable at Q4), but suffering of slow pre-processing times on very large contexts. I’d like to see if we can go beyond the 40 GB VRAM limit that currently exists with Vulkan, so that even larger models could fit in this space. Right now, the key advantage of the Framework Desktop as a LLM server is that it consumes very little energy compared to a Nvidia-equipped machine, and it can hold several models in memory at the same time. Could be a good fit for agentic workflows, for example.
Another option may be to pair a small Nvidia GPU directly on the Framework Desktop (using a PCIexpress adapter) and that may be the best of both worlds for LLM inference. Not sure if llama.cpp would handle the mixed archtecture well, but if it does, that could be really fun.
I will be back a little later as I continue my tests. More models, more games, more use cases - so that we have a complete understanding of what we can do with this.
Stay tuned.